AI Academy | テキスト
⇑スクレイピングで使うコマンド
==============================
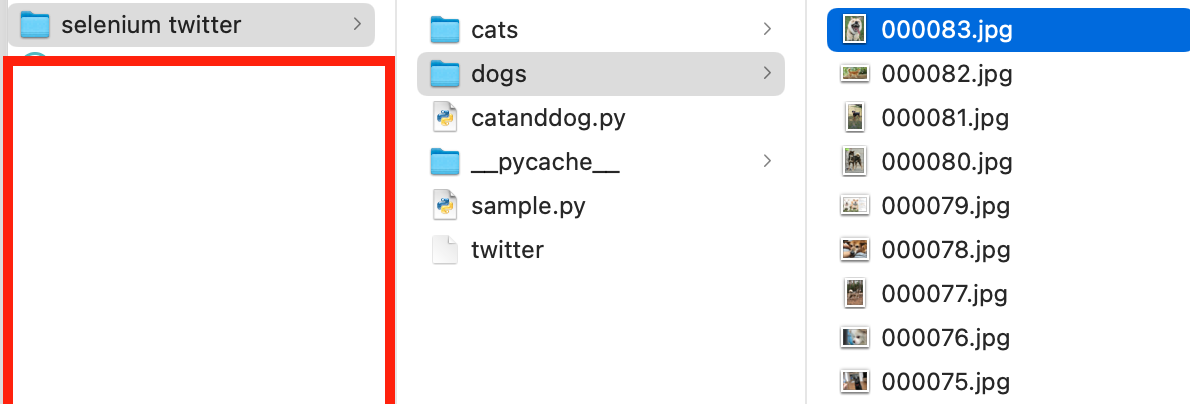
icrawlerについて 犬と猫の画像を収集し保存する
Macならターミナル、Windowsならコマンドプロンプト
Jpyter Notebookのセルや、Colabのセル
Bing検索エンジンから、犬と猫の画像をそれぞれ10枚ずつダウンロード
下記コードをテキストエディタで作成 該当ディレクトリに保存
from icrawler.builtin import BingImageCrawler
crawler = BingImageCrawler(storage={"root_dir": "dogs"})
crawler.crawl(keyword="犬", max_num=100)
# Googleの場合、クローリングが出来ない場合があります。
# from icrawler.builtin import GoogleImageCrawler
# crawler = GoogleImageCrawler(storage={"root_dir": "cats"})
# crawler.crawl(keyword="猫", max_num=10)
from icrawler.builtin import BingImageCrawler
crawler = BingImageCrawler(storage={"root_dir": "cats"})
crawler.crawl(keyword="猫", max_num=100)
catanddog.pyという名前で保存
cd で事前に該当ディレクトリに移動する
python catanddog.py で実行
catsと dogsのフォルダが作成され画像が保存された
=============SafariでのWebdriverについて=====================
qiita.com
sudo pip3 install selenium
from selenium import webdriver # Safariを指定して起動 browser = webdriver.Safari() browser.get('https://mainichi.jp/')
safariはwebdriver 必要なし
====================================
qiita.com
上記URL参照にアレンジ
#https://aiacademy.jp/media/?p=341
coding: UTF-8
import urllib.request
from bs4 import BeautifulSoup
from urllib.request import urlopen
# アクセスするURL
url = "http://www.nikkei.com/markets/kabu/"
## URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
# ※このコードはurlopen関数に渡す引数に関しての構文です。この1行だけでは動作しません。
#urllib.urlopen(url[, data[, proxies[, context]]])
html = urlopen(url)
##data = html.read()
##decoded_data = data.decode('utf-8')
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(html, "html.parser")
# タイトルを文字列を出力
print (soup.title.string)
↓
コマンドにて
python getNikkeiWebPageTitle.py
↓
株式: 日経電子版 と出力された
日本経済新聞 のHPにて 赤枠を左クリック
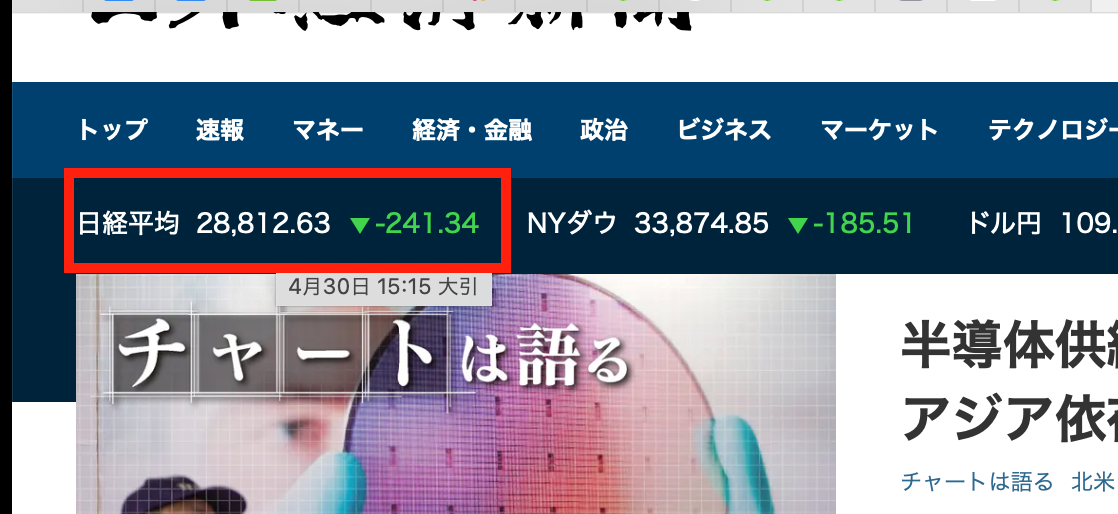
「株式」nを選択
数値部分を右クリック→「要素の詳細を表示」
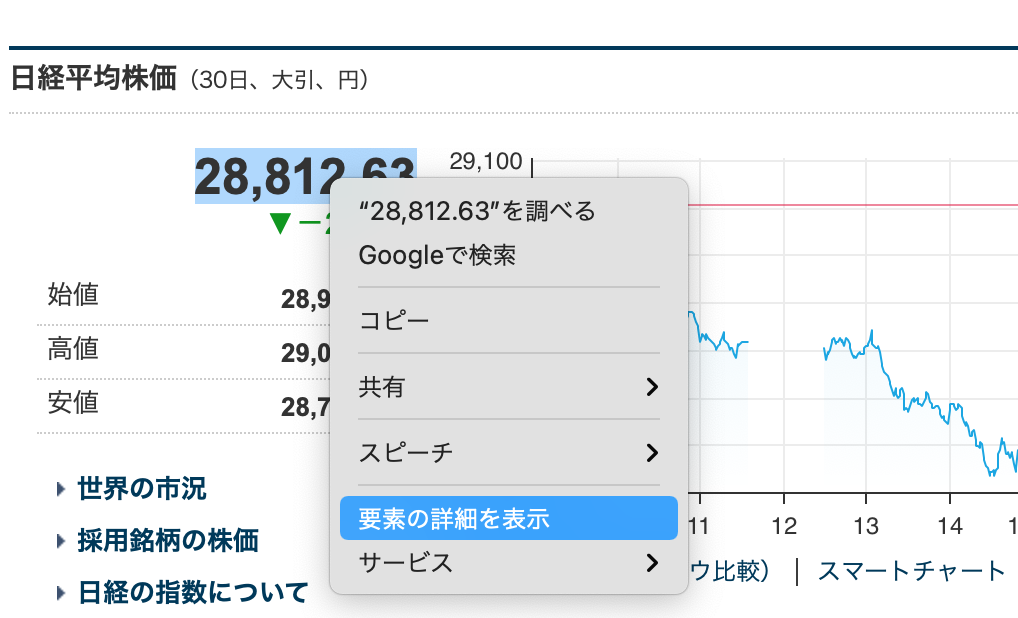
選択部分のソースが表示される
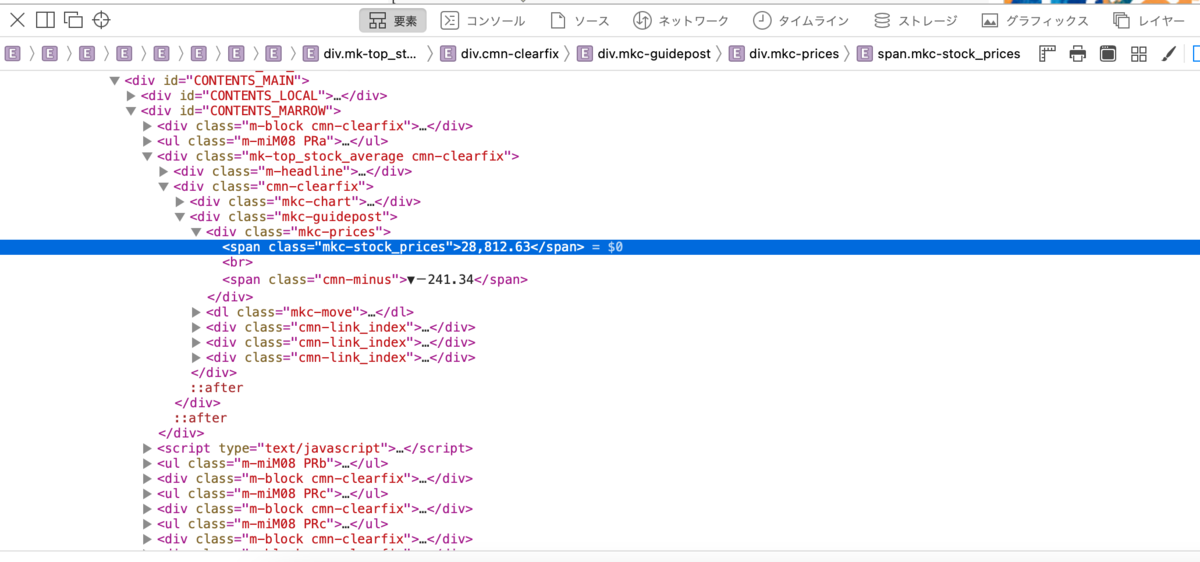
<span class="mkc-stock_prices">28,812.63</span> のコピー方法
右ダブルクリック?→コピー→HTML
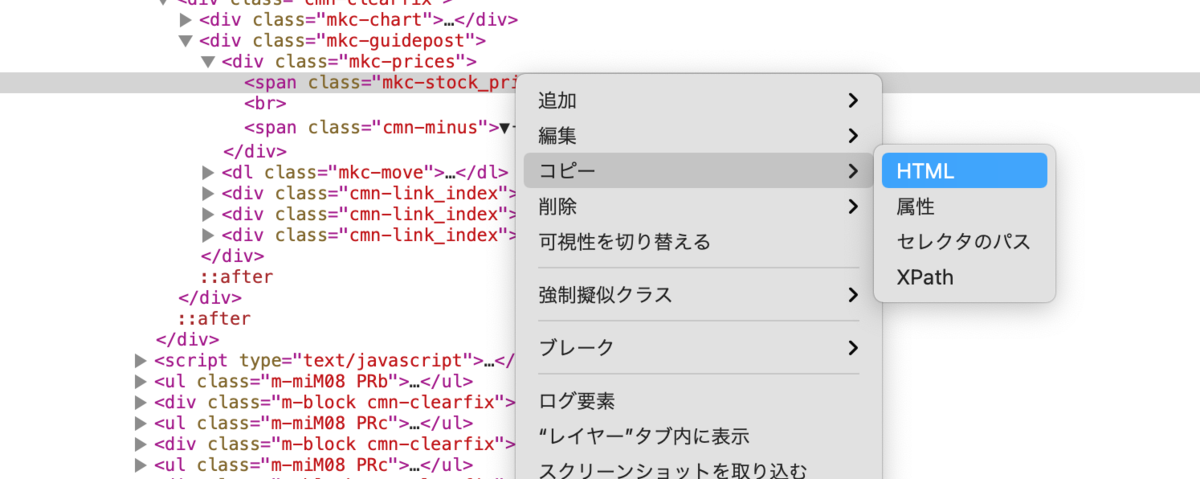
span要素のclass="mkc-stock_prices
位置を把握した
コードはこれ↓
# coding: UTF-8# coding: UTF-8import urllib.request
from bs4 import BeautifulSoup
from urllib.request import urlopen
# アクセスするURLurl = "http://www.nikkei.com/markets/kabu/"
## URLにアクセスする htmlが帰ってくる → <html><head><title>経済、株価、ビジネス、政治のニュース:日経電子版</title></head><body....
# ※このコードはurlopen関数に渡す引数に関しての構文です。この1行だけでは動作しません。#urllib.urlopen(url[, data[, proxies[, context]]])html = urlopen(url)##data = html.read()##decoded_data = data.decode('utf-8')
# htmlをBeautifulSoupで扱うsoup = BeautifulSoup(html, "html.parser")
# span要素全てを摘出する→全てのspan要素が配列に入ってかえされます→[<span class="m-wficon triDown"></span>, <span class="l-h...span = soup.find_all("span")
# print時のエラーとならないように最初に宣言しておきます。nikkei_heikin = ""
#<span class="economic_value_now a-fs26">28,812.63</span># for分で全てのspan要素の中からClass="mkc-stock_prices"となっている物を探しますfor tag in span: # classの設定がされていない要素は、tag.get("class").pop(0)を行うことのできないでエラーとなるため、tryでエラーを回避する try: # tagの中からclass="n"のnの文字列を摘出します。複数classが設定されている場合があるので # get関数では配列で帰ってくる。そのため配列の関数pop(0)により、配列の一番最初を摘出する # <span class="hoge" class="foo"> → ["hoge","foo"] → hoge string_ = tag.get("class").pop(0)
#<span class="economic_value_now a-fs26">28,812.63</span> # 摘出したclassの文字列にmkc-stock_pricesと設定されているかを調べます if string_ in "mkc-stock_prices": # mkc-stock_pricesが設定されているのでtagで囲まれた文字列を.stringであぶり出します nikkei_heikin = tag.string # 摘出が完了したのでfor分を抜けます break except: # パス→何も処理を行わない pass
# 摘出した日経平均株価を出力します。print (nikkei_heikin)
# タイトルを文字列を出力#print (soup.title.string)
#https://aiacademy.jp/media/?p=341
↓
ターミナルにて
python getNikkeiWebPageTitle.py
↓画像の数値が出た
28,812.63
参照URLにはCSVに出力される方法も記載される方法もあったが一旦ここまでで終わり
↓いつかしたい
Python Webスクレイピング テクニック集「取得できない値は無い」JavaScript対応@追記あり6/12 - Qiita