はじめに
Twitterにて いろんな方が ピン留めしている 自己紹介等を見て
自分も記載してみようと思ったのですが
Twitter に収まりきらなさそうだったのと 追加で記載することが多そうなので
ブログに記載してみようと思ったのがきっかけです
自己紹介
まだまだ作成したいものは沢山あるのですが 上記に集中して取り組んでいます
勤務可能な会社さんあればリモートワークにてトータルで週2働ければ嬉しいなと思っています


④Environments → create→ 下記ポップアップが出る Name部分は好きな名前で今回はpracticeと付けた MAC Windowsともに最新バージョンは3.8だがopencv使うならopencvが3.7までしかバージョン出てないので今段階3.7を選択した→ポップアップ内のcreateで作成 結構時間がかかる



こんな感じでSuccessfully Installedと記載があってもどこを探してもない状態not found になる


⑥完了後 右上の検索枠にて
必要なライブラリがインストールされているかを確認する。
pandas numpy pillow (PILの代わり) matplotlib (opencv)
scikit-learn 等 各自必要な分野で異なるのでその都度インストール
※Jupyternotebookを使用する場合 「Home」→ 該当の仮想環境を開く(最初base(root)になっているがpracticeを選択肢変更)→practiceになっている状態でjupyternotebook 下のlaunchを押す

ブラウザに開かれる

令和4年11月23日)
Anacondaで上記 名前をつけて仮想環境をつくるか もともと入っているbaseにて仮想環境を使用すれば問題ないです
MACではAnacondaをインストールすれば勝手に接続可能なPath が出てきて選択して接続可能
令和2年11月30日→令和3年11月6日
はじめに
内容
知って役立つ労働法~働くときに必要な基礎知識~ |厚生労働省
さらに、特に重要な次の6項目については、口約束だけではなく、きちんと書面を交付し なければいけません(労働基準法第 15 条)。
1 契約はいつまでか(労働契約の期間に関すること)※
2 期間の定めがある契約の更新についてのきまり(更新があるかどうか、更新する場
合の判断のしかたなど)
3 どこでどんな仕事をするのか(仕事をする場所、仕事の内容)
4 仕事の時間や休みはどうなっているのか(仕事の始めと終わりの時刻、残業の有無、
休憩時間、休日・休暇、就業時転換(交替制)勤務のローテーションなど)
5 賃金はどのように支払われるのか(賃金の決定、計算と支払いの方法、締切りと支
払いの時期)
6 辞めるときのきまり(退職に関すること(解雇の事由を含む))
これら以外の労働契約の内容についても、労働者と会社はできる限り書面で確認する必 要があると定められています(労働契約法第 4 条第 2 項)。
労働契約を結ぶことによって、会社は「労働契約で定めた給料を払う」という義務を負い ますが、一方でみなさんも、「会社の指示に従って誠実に働く」という義務を負うことになり ます。
1 労働者が労働契約に違反した場合に違約金を支払わせることや、その額をあらかじ め決めておくこと(労働基準法第 16 条)
たとえば、会社が労働者に対し、「1年未満で会社を退職したときは、ペナルティとして 罰金10万円」「会社の備品を壊したら1万円」などとあらかじめ決めておいたとしても、 それに従う必要はありません。もっとも、これはあらかじめ賠償額について定めておくこ とを禁止するものですので、労働者が故意や不注意で、現実に会社に損害を与えてし まった場合に損害賠償請求を免れるという訳ではありません。
2 労働することを条件として労働者にお金を前貸しし、毎月の給料から一方的に天引き する形で返済させること(労働基準法第 17 条)
労働者が会社からの借金のために、やめたくてもやめられなくなるのを防止するため のものです。
3 労働者に強制的に会社にお金を積み立てさせること(労働基準法第18条) 積立の理由は関係なく、社員旅行費など労働者の福祉のためでも、強制的に積み立 てさせることは禁止されています。ただし、社内預金制度があるところなど、労働者の 意思に基づいて、会社に賃金の一部を委託することは一定の要件のもと許されていま
す。
実際に働き始めた後の解雇よりは解約理由が広く認められますので、学校を卒 業できなかった場合や所定の免許・資格が取得できなかった場合、健康状態が悪化し働く ことが困難となった場合、履歴書の記載内容に重大な虚偽記載があった場合、刑事事件を 起こしてしまった場合などには内定取消しが正当と判断
就業規則は、労働者の賃金や労働時間などの労働条件に関すること、職場内の規律な どについて、労働者の意見を聴いた上で会社が作成するルールブック
就業規則は、掲示したり配 布したりして、労働者がいつでも内容がわかるようにしておかなければいけないとされてい ますので(労働基準法第 106 条)
常時10人以上の労働者を雇用している会社は必ず就業規則を作成し、労働基準監督 署長に届け出なければいけません(労働基準法第 89 条)
8
就業規則の作成・変更をする際には必ず労働者側の意見を聴かなければいけません (労働基準法第 90 条)
就業規則の内容は法令や労働協約に反してはなりません(労働基準法第 92 条、労働契 約法第 13 条)
雇用保 険、労災保険、健康保険、厚生年金保険に加入しており、その会社で働く従業員にはそれ らの制度が適用されますよ、ということを示しています。
労働者が失業した場合に、生活の安定と就職の促進のための失業等給 付を行う保険制度です。
勤め先の事業所規模にかかわらず、11週間の所定労働時間 が20時間以上で231日以上の雇用見込がある人は派遣社員、契約社員、パートタイ ム労働者やアルバイトも含めて適用対象となります。雇用保険制度への加入は会社の 責務であり、自分が雇用保険制度への加入の必要があるかどうか、ハローワークに問い 合わせることも可能です。保険料は労働者と会社の双方が負担します。
失業してしまった場合には、基本手当(→P.33 参照)の支給を受けることができます (額は、在職時の給与などによって決定されます)。雇用保険に関する各種受付はハロ ーワークで行っています。
労働者の業務が原因の怪我、病気、死亡(業務災害)、また通勤の途中 の事故などの場合(通勤災害)に、国が会社に代わって給付を行う公的な制度です。
労働基準法では、労働者が仕事で病気やけがをしたときには、会社が療養費を負担 し、その病気やけがのため労働者が働けないときは、休業補償を支払うことを義務づけ ています(労働基準法第 75、76 条)。しかし、会社に余裕がなかったり、大きな事故が起 きたりした場合には、十分な補償ができないかもしれません。そこで、労働災害が起きた ときに労働者が確実な補償を得られるように労災保険制度が設けられています。
基本的に労働者を一人でも雇用する会社は適用され、保険料は全額会社が負担しま す。
労働災害に対する給付は、パートタイム労働者やアルバイトも含むすべての労働者が 対象であり、仮に会社が加入手続きをしていない場合でも、給付を受けられます。各種 受付は労働基準監督署で行っています。
健康保険
労働者やその家族が、病気や怪我をしたときや出産をしたとき、亡くなった ときなどに、必要な医療給付や手当金の支給をすることで生活を安定させることを目的と した社会保険制度です。病院にかかる時に持って行く保険証は、健康保険に加入すること でもらえるものです。これにより、本人が病院の窓口で払う額(窓口負担)が治療費の3割 となります。
健康保険は1国、地方公共団体又は法人の事業所あるいは2一定の業種(※)であり 常時5人以上を雇用する個人事業所では強制適用となっており、適用事業所で働く労働 者は加入者となります(派遣社員、契約社員、パートタイム労働者、アルバイトでも、1日ま たは1週間の労働時間及び1か月の所定労働日数が、通常の労働者の4分の3以上あれ ば加入させる必要があります。ただし、2か月以内の期間を定めて働く臨時の労働者など は加入の対象とはなりません。)。また、保険料は、会社と労働者が半々で負担します。
※ 一定の業種・・・製造業、土木建築業、鉱業、電気ガス事業、運送業、清掃業、物品販 売業、金融保険業、保管賃貸業、媒介周旋業、集金案内広告業、教
育研究調査業、医療保健業、通信報道業など
厚生年金保険
労働者が高齢となったり、何らかの病気や怪我によって身体に障害 が残ってしまったり、大黒柱を亡くしてその遺族が困窮してしまうといった事態に際し、保 険給付を行い、労働者とその遺族の生活の安定と福祉の向上に寄与することを目的とし た制度です。
厚生年金保険適用事業所は、健康保険と同様
1国、地方公共団体又は法人の事業所 あるいは
2一定の業種(※)であり常時5人以上を雇用する個人事業所では強制適用とな っており、適用事業所で働く労働者は加入者となります(派遣社員、契約社員、パートタイ ム労働者、アルバイトでも、1日または1週間の労働時間及び1か月の所定労働日数が、 通常の労働者の4分の3以上あれば加入させる必要があります。ただし、2か月以内の期 間を定めて働く臨時の労働者などは加入の対象とはなりません。)。また、保険料は、会社 と労働者が半々で負担します。
※ 詳しく知りたい場合は以下の相談窓口にご相談ください。
・ 雇用保険 ... ハローワークまで。
・ 労災保険 ... 労働基準監督署まで。
・ 健康保険 ... ご加入の全国健康保険協会都道府県支部又は健康保険組合まで。
2階建ての構造で、国内に居住する 20 歳以上 60 歳未満の すべての方が国民年金に加入し(国民皆年金)、高齢期になれば加入期間に応じて定 額の基礎年金(1階部分)を受け取ります。(基礎年金の半分は税金で賄われていま す。)
これに加えて、会社員は厚生年金、公務員等は共済組合に加入し、基礎年金の上乗 せとして、会社員・公務員等として「働いた期間」と「給料」に応じた報酬比例の年金(2 階部分)を受け取ることになります。(保険料は、会社と本人が半々で負担します。)
※ なお、厚生年金と共済年金は、平成27年10月に統合
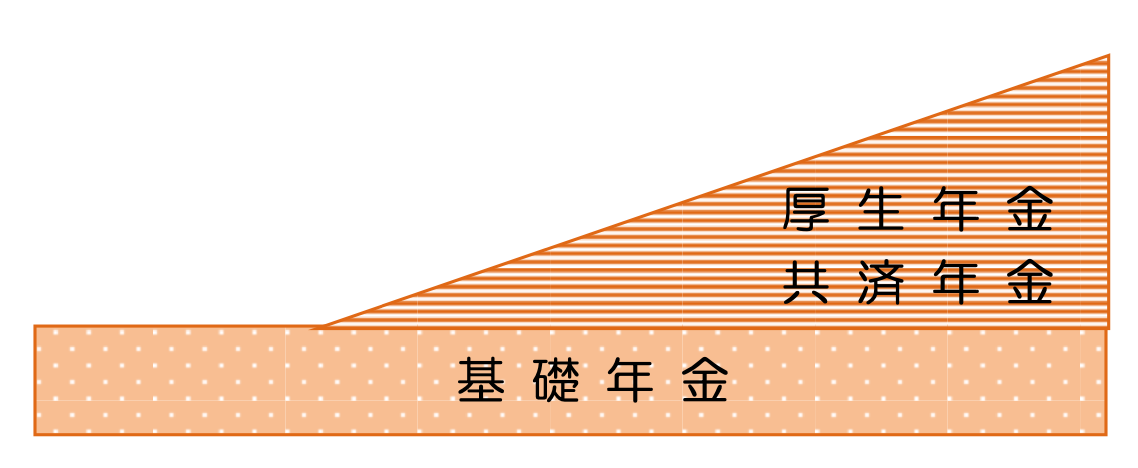
「老齢年金」だけでなく、障害を負った場合の「障害年金」、配偶者 が亡くなった場合の「遺族年金」など、現役世代も、所得を失った場合に受け取ることの できる年金もあります。
実際に労働条件が違っていた場合には、労働者は約束通りにする ように要求できますし、そのことを理由にすぐに契約を解除することが認められています (労働基準法第 15 条)。この場合は有期労働契約の契約期間途中であっても、退職するこ とができます。
最低賃金は、たとえ労働者が同 意したとしても、それより低い賃金での契約は認められません。もし、みなさんが会社に頼 まれて時給500円で働くことに同意してしまったとしても、その約束は法律によって無効と なり、最低賃金額と同額の約束をしたものとみなされます。したがって、最低賃金との差額 ×働いた時間分(東京なら388円×時間)を後から請求することができます。
※ 平成27年4月現在。
4つの原 則が定められています(労働基準法第 24 条)。
1通貨払いの原則 賃金は現金で支払わなければならず、現物(会社の商品など)で払ってはいけません。ただ
し、労働者の同意を得た場合は、銀行振込みなどの方法によることができます。また、労働協 約で定めた場合は通貨ではなく現物支給をすることができます。
2直接払いの原則 賃金は労働者本人に払わなければなりません。未成年者だからといって、親などに代わり
に支払うことはできません。
3全額払いの原則 賃金は全額残らず支払われなければなりません。したがって「積立金」などの名目で強
制的に賃金の一部を控除(天引き)して支払うことは禁止されています。 ただし、所得税や社会保険料など、法令で定められているものの控除は認められてい ます。それ以外は、労働者の過半数で組織する労働組合、または労働者の過半数を代表
する者と労使協定を結んでいる場合は認められます。
4毎月1回以上定期払の原則 賃金は、毎月1回以上、一定の期日を定めて支払わなければいけません。したがって、「今
月分は来月2か月分まとめて払うから待ってくれ」ということは認められませんし、支払日を「毎 月20日~25日の間」や「毎月第4金曜日」など変動する期日とすることは認められません。た だし、臨時の賃金や賞与(ボーナス)は例外です。
その他のきまり
労働者が、無断欠勤や遅刻を繰り返したりして職場の秩序を乱したり、職場の備品
を勝手に私用で持ち出したりするなどの規律違反をしたことを理由に、制裁として、賃
金の一部を減額することを減給といいます。一回の減給金額は平均賃金の1日分の半 額を超えてはなりません。また、複数回規律違反をしたとしても、減給の総額が一賃金 支払期における金額(月給なら月給の金額)の10分の1以下でなくてはなりません。
会社の責任で労働者を休業させた場合には、労働者の最低限の生活の保障を図る
ため、会社は平均賃金の6割以上の休業手当を支払わなければなりません。したがっ て、「働いていないから給料がもらえないのは仕方ない」ということはなく、休みが会社 の都合である以上、一定程度の給料は保障されています。
労働基準法には給与明細書を必ず渡さなければいけないというきまりはありません
が、所得税法において、給与を支払う者は給与の支払を受ける者に支払明細書を交 付しなくてはならないと定められています。したがって、会社には従業員に給与明細書 を交付する義務があり、給与を支払う際に交付しなければいけません。ただし、給与の 支払いを受ける者の承諾を得て、電磁的方法により提供することができます。
給与明細書は、給料がいくら支払われたのか、税金や保険料はいくら引かれている のかなど重要な証拠となるものですから、内容をしっかり確認し、万が一のトラブルに 備えて保管しておくことが大事です。
https://www.jtuc-rengo.or.jp/activity/gender/data/equality-month/slide_harassment.pdf
https://www.gender.go.jp/kaigi/senmon/boryoku/houkoku/pdf/honbun_hbo09.pdf
まとめ
一部だけですが勉強になりました
労働法と言っても、労働者側が非常識なことをすればそれに伴う 賠償責任等もあるので 雇用側も労働者側も相手に失礼がないようにするべきだと思いました
はじめに
医療法について 雑多にまとめました
内容
↓最初の感じ↓
第一章 総則
医療を受ける者による医療に関する適切な選択
医療の安全を確保
医療を受ける者の利益の保護及び良質かつ適切な医療を効率的に提供する体制の確保を図り、もつて国民の健康の保持に寄与することを目的
第一条の二
生命の尊重と個人の尊厳の保持を旨
医療の担い手と医療を受ける者との信頼関係に基づき
及び医療を受ける者の心身の状況に応じて行われるとともに、その内容は、単に治療のみならず、疾病の予防のための措置及びリハビリテーションを含む良質かつ適切なもの
2 医療は、国民自らの健康の保持増進のための努力を基礎
第一条の三 国及び地方公共団体は、前条に規定する理念に基づき、国民に対し良質かつ適切な医療を効率的に提供する体制が確保されるよう努めなければならない。
5 医療提供施設の開設者及び管理者は、医療技術の普及及び医療の効率的な提供に資するため、当該医療提供施設の建物又は設備を、当該医療提供施設に勤務しない医師、歯科医師、薬剤師、看護師その他の医療の担い手の診療、研究又は研修のために利用させるよう配慮しなければならない。
第一条の五 この法律において、「病院」とは、医師又は歯科医師が、公衆又は特定多数人のため医業又は歯科医業を行う場所であつて、二十人以上の患者を入院させるための施設を有するものをいう。
2 この法律において、「診療所」とは、医師又は歯科医師が、公衆又は特定多数人のため医業又は歯科医業を行う場所であつて、患者を入院させるための施設を有しないもの又は十九人以下の患者を入院させるための施設を有するも
まとめ
医療法についてまだ読み進めている最中なのでコツコツしようと思いました
以前は昔の読みにくい文章だったようですが途中から皆が読めるようにということで現代文のような形に読みやすくなったようです
読み進めていくと読書のような形で面白く感じました
MENTAを使用し始めて ある程度 時間が経ったので備忘録も兼ねて 記載しようと思い、今回記事を書きました
MENTAにて 呼ばれているように 教える側を メンター 教えてもらう側をメンティーと以下から使用していきます
環境
下記の画面にて 新規登録を行います
様々なSNSなどの選択肢あるので自分が使用しやすいものを選択し登録
今だと登録で300円オフクーポン
私のときもそうだったきがします
最近 手数料が更に高くなったりがあったので今後はどうなるかは不明です

下記のように必要な情報を入力

メールアドレスであれば該当のメールアドレスに仮登録のメールが届きます
認証を完了する のボタンを押すと 使用開始できます

(PC画面の見方のみになっております 申し訳ないです)
黒枠部分の 「プロフィールを確認」 をクリック

「プロフィールを編集」をクリック

または 設定 タブの 「プロフィール設定」から飛ぶ

ユーザー名・アイコン・メールアドレス・自己紹介 等を設定していきます

については メンターの方の返答ときの時間、利用者側が質問を投稿する時間に関係すると思うので
活動時間がおおよそ同じの方が良いかと思われました
すぐ解決しそうな質問でも自分である程度調べたけど分からなかった となったときに内容によりますが 返答がすぐあれば学習速度・進捗度も違います
メンターの方もその部分が合致していれば 返信が遅い等のメンティーの不安が発生しにくいのではないかと思いました

については 3000円〜10000円が標準設定です
MENTAのどこかで 目安予算が高いほうが良い というアドバイスがあります
しかし、スクールの費用に比べれば安価ですが この値段が妥当だと思います
(自分にとっては 質によりますが、6000円 7000円が上限だと思ってます 他技術によってはこの値段設定より高めが妥当の場合もあります)

については人によってまちまちですが 言語レベル等の把握になり、メンターの方が困らない。メンターとメンティーの求めていたものや与えられるものの不一致を回避できるのである程度は設定する必要があるかと思いました
私であれば 医療に関わる人間であり作製していくものも医療に関わるものなので医療事務の年数等(必要ないかもしれませんが。。)

については 自分の成果物や作成したものがあるのであれば
メンターとメンティーの不一致がないように必要かと思いました
メンターの方がメンティーの方の言語レベルやどのぐらいまでの組み立て等ができるか等の判断基準になるので私は必要だと思いました
(人によってはそこまで見てないメンターの方も居るので そのような方はその段階で契約まではいかなくていいと思います)

については スキル等を把握してもらうために必要あればと思います
公式にて画像のようにメッセージがあるように メンターの方が貼ると良いかと思います
メンティーの方は随時です

については設定を必ず行うと良いと思います
メンターの方への検索等にも引っかかりやすくなると思うので。

下記画像にある
も必須と言っていいほど過言ではないです

最後にある
は必ず設定していたほうがよいです 「受け付ける」にしていて最初の頃は提案してくれる方もいるので良いと思います

メンターの方を探す際に 自分で探すことも出来るのですが 如何せん人数が多いので 特にIT業界未経験の人にとっては難易度が若干高めだと思います
そのため
メンターを募集 という機能があります

ダブルクリックすると下記画面になります

タイトル は分かりやすく記載
カテゴリーについては エンジニア というカテゴリでも複数あるので該当のものを選びます

タグ
画像にもあるように ここはとても重要です
当てはまるもの、近いものを選ぶと 募集する内容と近いメンターの方に通知等設定している方には届きます

募集スタイル
単発もいいですが月額のほうがコストパフォーマンスもよいです
人によっては単発で行って良いメンターの方を探す方もいるので人それぞれと思います
私は月額を選びました

※月額の注意点は 自動更新機能があるのでその点 注意です
その際にきちんとメールにて通知がきます

!あとで
画像イメージ

はメンターの方は必要だと思いますが、メンティーの方は必要ないと思います 私も設定してません

これについては どのように記載すればいいかわからない際も テンプレートがあるのでそちらを活用しながら 記載します

こちら平均価格帯が高めを推奨されていますが 私は最初の段階で3000〜10000円できちんと募集が来ました
まずはそのぐらいで良いと思います
(特殊なものでない限り)

こちらについてはあまり意識してませんでした 最大で14日後まで設定できるので 自分がいつまで募集するか いつまで応募がほしいかで変わると思います
感覚としては 投稿した時点ですぐにMENTAないでメッセージが来るので余裕もたして3日あれば募集は来ると思います
基本 投稿してすぐ来るので短期間でいえば1日後 の設定でも可能です


こちらは必ず 「公開する」にしないと そもそも見れないので募集が来ないです
そのため必ず「公開する」になっているかチェックが必要です

過去に契約したことがあるメンターの方で気まずい等あれば 任意ですがチェックをつけて 表示しない 機能もあります

最後に 禁止事項確認し 保存ボタンを押せば完了です
🌟ここでポイントですが 投稿日時が早いものが 募集履歴の一番上に来るので 投稿した際の該当メンターの方への通知の可能性もありますが
1回内容を保存してから投稿・公開でなく 今現在のリアルタイムの時間で投稿することをオススメします
投稿したものは 投稿管理 タブ から 作製した募集で一覧が見れて、削除できます

メンターの方のページの飛ぶと ○の部分に 画像があります
オンラインになった時間を隠す機能もありそうですが(メンターの方を募集した際に その方からメールがきたがその時間が最終ログインになっていなかったため)
最終ログインを念の為 チェックし あまりに 最終ログイン時間がかけ離れている際は見送ります(自分で探した際に1年前が最終ログインという方がザルにいたため)
メンタースコアについては重要かもしれないですが、誰かれ構わず送っている方(会社の方)もいるので あまり参考にしてません
評価についても参考にしてません ただし低評価レビューは参考程度に見てます
その低評価レビューが本当であれば自分が受け止められるかどうかで判断してます
契約中や累計人数は 何人かのスタッフで構成されている方や 会社さん規模でされているアカウントもあるのでその場合は数がすごいです
しかし大規模的にしているメンターの方は 基本 関連するワードが含まれる募集を投稿したメンティーには同じようなメール内容でメールをしています
(なぜかいつも投稿するとその方から来るので Bot化しているのかもしれません しかしなぜか前のメール内容は消されています)
なのでこれについてもあまり重要視してません
フォロー人数とフォロワー人数も重要視してません
私が重要視していたのは医療に関わるため、本人確認 と NDAという機密保持契約です
これがない場合、自分の情報が流れる可能性もあるので重要視しました

他にも学びログ、目標設定 等の機能があるのですが メンターの方を募集という点ではこれが全てだと思うので一旦終了します(メールの仕方等もあるかもしれませんがまた発見があれば書きます)
完全に未経験、スクール歴もない方であれば 大手のメンターの方で会社規模で回しているようなメンターの方がオールマイティーにされているので基礎を固めるのを最初にしたいならそちらが良いと思います
スクールを卒業しある程度 基礎が固まっているのであれば 上記のような方は避け 個人、少人数でメンターアカウントを運営されている 方が良いと思います
また MENTAには事前に 教えてもらったりすることは禁止されています
そのため 契約してから質問しましょう
ただし 契約内容、多少の内容 等 ある程度 相手のことを確かめるための質問は良いと思います メンターの方であればメンティーの方はわからない方も居ると思うので それについて契約前にお答えするのは難しいですと言っていただけるとありがたいですね
私はスクールに1回通っており、スクールは高すぎるのMENTAを上手く活用できればと思っています
2022-08-13
2022-09-05